Support IA pour SaaS solo en 2026 : 80% des tickets résolus sans toi
L'IA résout 80% de tes tickets pour 0,62€ pièce en 2026, contre 7,40€ avec un humain. Le stack qui automatise ton support sans casser ton NPS, et les 3 cas où tu dois rester en façade.

En octobre 2025, je passais 80 heures par mois sur le support de WhatSetter. Solo, 30 tickets par jour, ma soirée commençait à 22h. En février 2026, je passe 12 heures par mois. Pas parce que j'ai pris quelqu'un, parce que j'ai branché un agent IA qui résout 80% de mes tickets. Le coût stack : 49€/mois. Le temps gagné : 68 heures par mois, soit 3400€ de shadow ROI. Voici exactement ce qui marche, ce qui casse, et les 3 cas où l'IA n'a rien à faire.
Ce chantier vient juste après un onboarding qui retient. L'onboarding évite que tes users churnent avant d'utiliser le produit. Le support IA évite qu'ils churnent une fois dedans. Les deux sont une seule chaîne, pas deux disciplines.
Pourquoi 2026 est l'année où l'IA support devient viable pour les solos
Trois shifts techniques (Claude Sonnet 4.6 sortie fin 2025, RAG mature, helpdesks IA-natifs comme Crisp et Plain) ont rendu l'auto-résolution accessible aux solos en 2026. Les agents IA résolvent 60 à 80% des tickets sans humain. Coût IA 0,62€ par résolution contre 7,40€ humain, facteur 12. CSAT moyen IA 78%, équivalent au humain sur les routine intents. Le gap est fermé.
En 2023, un chatbot scripté résolvait 30 à 40% des tickets et ses réponses sentaient le copier-coller à 100 mètres. En 2026, un agent IA bien câblé en résout 80% et le client ne se rend pas compte qu'il parle à une machine sur 7 cas sur 10. Le shift n'est pas dans le marketing des outils, il est dans la combinaison Claude Sonnet 4.6 plus RAG sur tes docs.
Sur WhatSetter, l'avant-après chiffré tient en 4 lignes. Octobre 2025 : 30 tickets/jour, 100% sur ma table, 80h/mois. Février 2026 : 6 tickets/jour me remontent, 24 résolus par l'agent, 12h/mois. Pas un client perdu sur la transition. CSAT passé de 4,1 à 4,3 (oui, l'IA répond plus vite, donc parfois mieux). Le seul prix : 4 semaines de setup propre.
87% des leaders du marché (Intercom 2026 Customer Transformation Report) prévoient d'investir dans l'IA support cette année. Pour un solo, ne pas le faire en 2026 c'est laisser 60-80h/mois sur la table et payer 12× le prix par ticket résolu. Pour aller plus loin sur le calendrier produit où ce chantier s'insère, lis le calendrier 12 semaines complet qui le pose en semaine 11.
Le stack 2026 qui marche : helpdesk IA-natif, LLM grounded, RAG
Quatre briques fixes en 2026 : un helpdesk (Crisp, Plain ou Intercom selon profil), un LLM (Claude Sonnet 4.6 pour la précision ou Haiku 4.5 pour le volume), un RAG sur tes docs et ton historique tickets, et 3 règles d'escalation. Coût total stack solo : 49 à 130€/mois. Au-delà de 200€/mois pour un solo, tu paies pour des features que tu n'utilises pas.
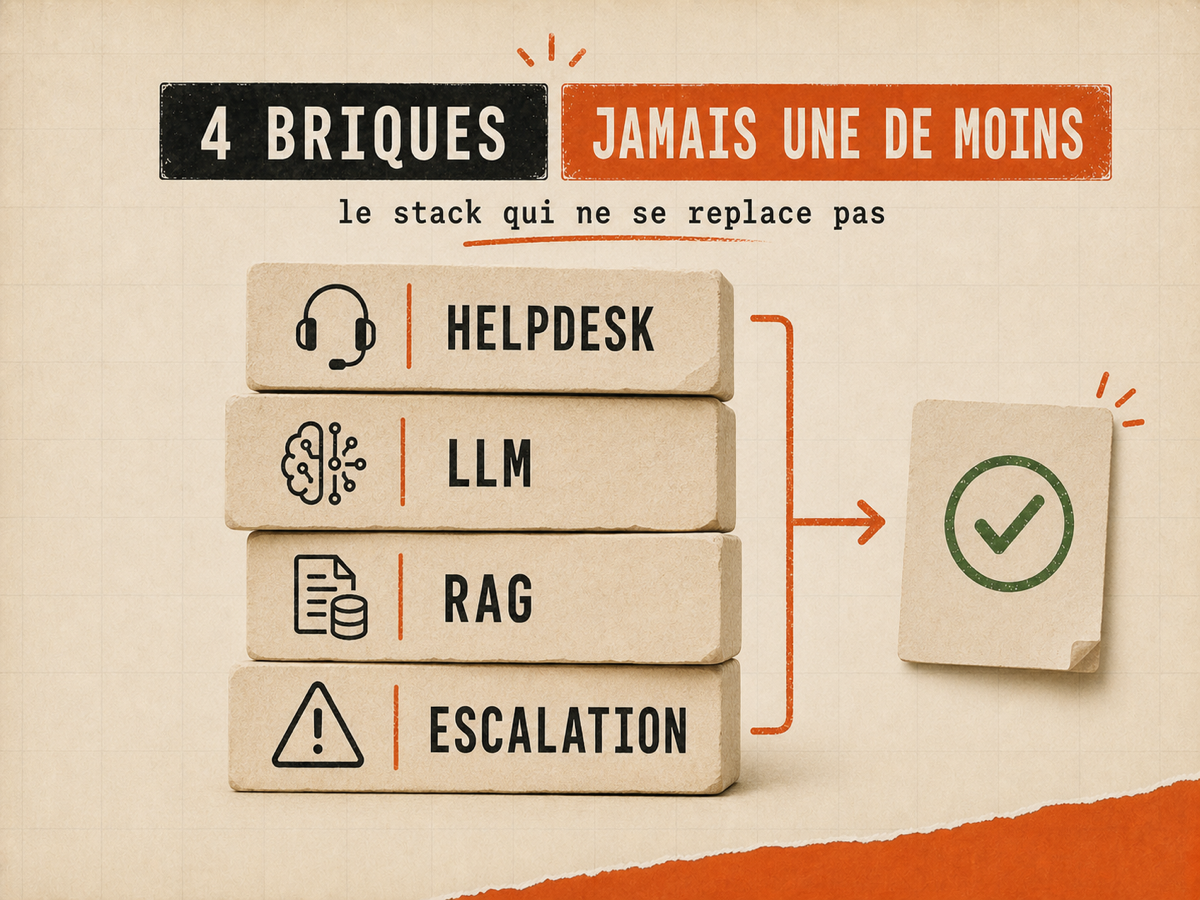
Sur WhatSetter, ma stack tient en trois lignes : Plain pour le helpdesk, Claude API directe pour le LLM, Pinecone pour le vector store du RAG. Coût mensuel total : 49€. Volume : ~600 tickets/mois, 76% résolus par l'agent, 24% me remontent. Vs Intercom Fin équivalent qui m'aurait coûté 200€+/mois sur le même volume. Pour un solo, le calcul est tranché.
Le piège classique, c'est de partir sur Intercom Fin parce que c'est le plus visible sur le marché. Pour un volume bas (sous 200 tickets/mois), le pricing variable de Fin (0,99$/résolution en plus du 29$/seat) explose ton coût par ticket. Crisp Essentials à 95$/mois flat avec AI inclus est plus prédictible. Plain, c'est custom B2B avec contrôle total sur le pricing au volume réel. Voici la grille :
| Helpdesk + IA | Prix /mois solo | AI inclus | Bon pour |
|---|---|---|---|
| Crisp Essentials | $95 flat | ✓ | Solo qui ne veut pas brancher 3 outils |
| Plain + Claude API | ~50-130€ | ✗ (à brancher) | Solo SaaS B2B technique |
| Intercom + Fin | $29 + $0,99/résolution | ✗ (Fin variable) | Quand tu scales >5 tickets/heure |
| Helpscout + AI Drafts | $25/seat | ✓ AI Drafts | Solo email-first |
Pour les founders qui veulent garder la main sur l'agent (et pas dépendre du SaaS du helpdesk), il y a un 5e setup viable : un subagent dédié au support directement câblé sur ton helpdesk via webhook. Plus complexe à setup, mais 0€/mois en surplus de l'API Claude. Pour un founder déjà à l'aise avec Claude Code, c'est l'option qui scale le mieux dans le temps.
Pourquoi RAG est non-négociable : 15-27% d'hallucinations sans, 0,7-1,5% avec
Un LLM sans grounding (RAG sur tes docs et ton historique tickets) hallucine 15 à 27% de ses réponses. Avec un RAG correctement câblé, le taux d'hallucination tombe à 0,7-1,5%. C'est la différence entre un agent fiable et un générateur de tickets de support sur l'agent lui-même. Sans RAG, ton agent invente des features qui n'existent pas.
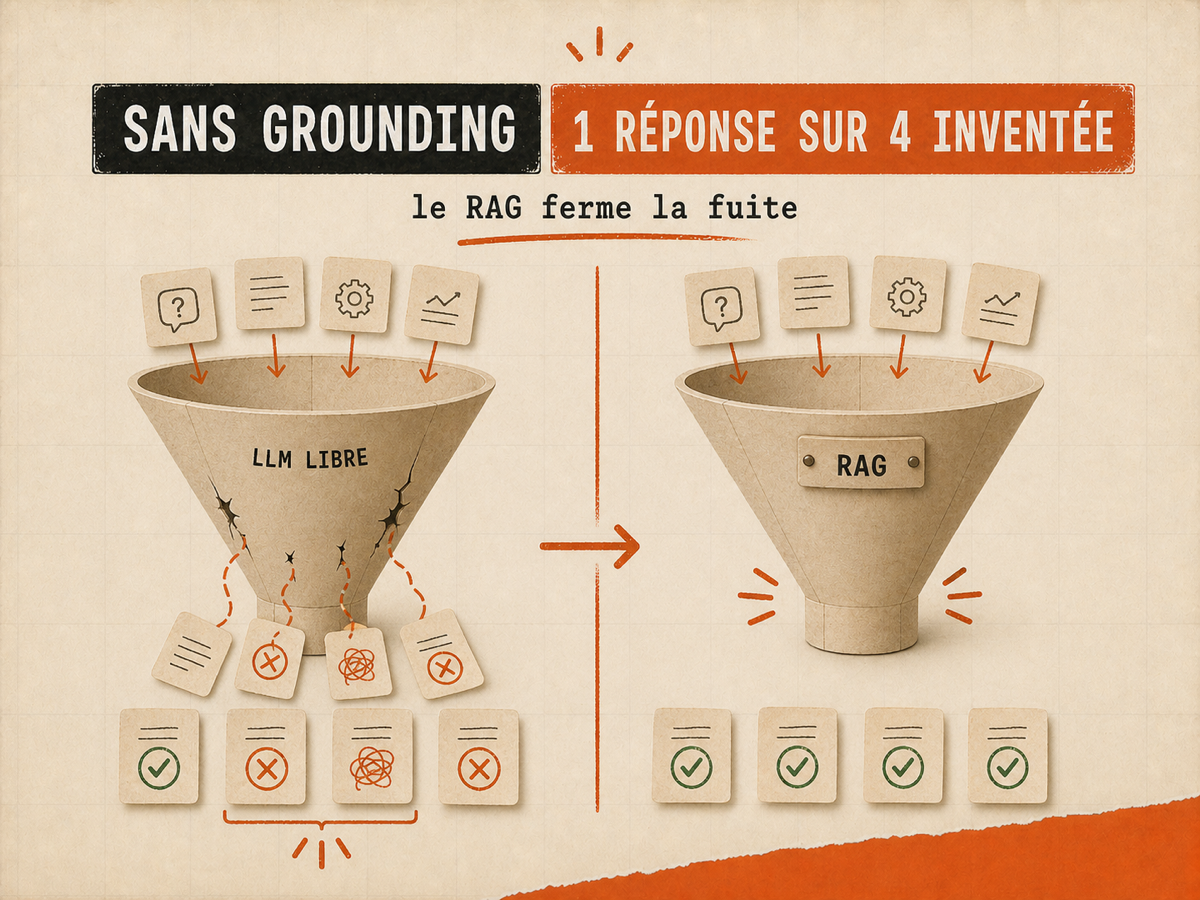
Le RAG, c'est juste ça : avant que Claude réponde, il cherche dans ton vector store (tes docs publiques plus tes 1000 derniers tickets résolus) les 5 chunks les plus pertinents pour la question, et il les injecte dans son contexte. C'est ce grounding qui empêche le modèle d'inventer. Pas de RAG = Claude répond à partir de sa training data généraliste, qui ne connaît pas ton produit.
Un founder qu'on accompagne dans le programme a démarré sur ChatGPT API directe, sans RAG sur ses docs. En une semaine, 4 hallucinations remontées par les clients : l'agent a inventé une feature "export CSV" qui n'existait pas, un plan tarifaire à 19€ qui n'existait pas non plus, et deux intégrations imaginaires. CSAT chuté de 4,2 à 3,4. On l'a obligé à brancher Pinecone sur ses docs avant de continuer. Hallucinations passées à zéro en 3 jours, CSAT remonté à 4,1 en 2 semaines.
Le grounding ne se câble pas en 5 minutes. Compte 2 à 4 heures pour faire ça proprement : embedding de tes docs publiques, embedding de tes 1000 derniers tickets résolus (avec l'output réel, pas juste la question), une query pipeline qui re-rank les chunks par similarité sémantique, et un prompt système qui force Claude à citer la source. Tout ça est documentable en spec, et la spec qui décuple Claude Code est exactement ce qu'il faut écrire avant de toucher à une ligne de code RAG.
Avant de mettre ton agent en prod, fais-le passer sur 50 tickets résolus du passé. Compare réponse IA vs ta réponse humaine. Si moins de 80% sont alignées, ton RAG est mal câblé. N'active pas le live tant que tu n'as pas franchi les 80%.
Les 3 lignes rouges à NE PAS automatiser : cancellation, billing, complaints
L'IA est excellente sur les structured intents (password reset CSAT 4,41/5, refund status 4,32/5). Elle est nulle sur les emotional intents (complaint handling 3,34/5, accuracy 61,2%). Trois cas où tu dois rester humain en façade : cancellation flow, billing dispute, complaint séquence. Le gap n'est pas un problème de prompt, il est structurel.

Sur les intents structurés, l'agent IA est en moyenne plus précis qu'un humain fatigué. Password reset à 98,2% d'accuracy, refund status à 95%, "où est ma facture" à 97%. CSAT toujours au-dessus de 4,2/5. Pour ce type de ticket, l'humain n'apporte rien sauf de la latence. Tu actives, tu mesures, tu vérifies. Aucun débat.
Sur les intents émotionnels, le tableau s'inverse brutalement. Complaint handling tombe à 3,34/5 de CSAT et 61,2% d'accuracy. Un client qui écrit "ça marche pas du tout, je vais demander un remboursement et laisser un avis 1 étoile" n'attend pas une réponse calibrée, il attend une présence humaine. L'IA qui sort un script de rétention sur ce ton fait empirer les choses dans 6 cas sur 10.
Un client WhatSetter a annulé en mode rage en mars 2026, 3 messages en 10 minutes, capslock, accusations. L'agent IA a tenté un script de rétention. Le client a posté un avis 1 étoile sur Trustpilot dans la foulée et a recommandé à 2 autres prospects de ne pas signer. Depuis, sentiment négatif détecté (analyse via Claude Haiku 4.5 en 200ms) = escalation immédiate vers moi, sans tentative de réponse IA. NPS récupéré en 2 semaines. La règle a coûté ~30 minutes à câbler, elle aurait dû être là dès le jour 1.
Structured (password, refund status, "où est ma facture", FAQ feature) = full IA. Transactionnel (changer de plan, ajouter user) = IA + confirm humain. Emotionnel (complaint, cancellation, dispute, urgent) = humain direct, IA en zéro façade.
Le calcul ROI : ce que tu économises vraiment en 2026
Un solo SaaS à 600 tickets/mois économise environ 3300€ par mois en valeur de temps avec un setup IA correct. Coût stack : 49 à 130€/mois. Facteur 25 à 70 sur le ROI. Mais le vrai gain n'est pas l'argent, ce sont les 60 à 80 heures par mois récupérées pour builder. C'est ce qui débloque le passage de la V1 à la V2.

Le math est simple. Sur 600 tickets/mois en mode full humain, à 7,40€ par résolution (chiffre Intercom 2026, qui inclut le temps de traitement et la latence de réponse), tu paies 4440€ équivalent-temps. Sur 600 tickets/mois en mode 80% IA + 20% humain : 480 × 0,62€ + 120 × 7,40€ = 297€ + 888€ = 1185€. Économie nette : 3255€/mois. Sur 12 mois, c'est 39000€ qui restent dans la trésorerie ou qui te paient un freelance à 80% pour autre chose.
Mais le chiffre qui compte vraiment, c'est le temps. Un founder VibesMoney 11, mars 2026, m'a sorti son tracking : 80 heures par mois sur le support en janvier, 12 heures en mars après 4 semaines de setup IA. Gain net 68 heures × 50€/h (son tarif freelance perçu) = 3400€/mois en shadow ROI. Mais surtout, il a relancé le build de sa V2 le mois suivant. Sans le setup IA, il était bloqué à itérer sur le V1 pendant 6 mois de plus. Le ROI réel n'est pas le coût économisé, c'est l'opportunité débloquée.
Ce calcul rend le pricing du SaaS plus solide aussi : avec un support qui scale par défaut, tu peux pricer ton premier client à un prix qui inclut un excellent support sans devoir le sacrifier au scale. Le pricing premium devient défendable parce que le support tient à 600 tickets/mois sans recruter.
Le piège n°1 : automatiser sans configurer les règles d'escalation
Le piège n°1, c'est de brancher l'IA et oublier les règles d'escalation. Un ticket qui devrait remonter chez toi (sentiment négatif, keyword cancellation, timeout 30 min sans résolution) reste en queue IA, pourrit, et le client churn. Sans 3 règles minimum, ton CSAT chute de 15 à 25 points en 4 semaines.
Les 3 règles minimum à câbler avant tout déploiement live, par ordre de criticité. Premièrement, sentiment négatif détecté (analyse Claude Haiku en parallèle de la conversation, score sentiment sous 0,3 = escalation). Deuxièmement, keywords critiques dans le ticket (cancel, refund, urgent, lawsuit, bug critique, lent, plante) = escalation directe. Troisièmement, timeout 30 minutes sans résolution = escalation par défaut. Sans timeout, un ticket peut tourner 8 heures dans la queue IA pendant que l'agent répète des FAQ.
Un founder qu'on a accompagné a setup l'IA sans escalation timeout, "pour voir comment ça tient". Un ticket "ça marche pas du tout, je vais demander un remboursement" est resté 8 heures dans la queue IA pendant que l'agent répétait des FAQ génériques. Client churné, MRR perdu, et avis négatif Trustpilot. On a setup l'escalation timeout 30 minutes ce soir-là, plus jamais arrivé. La règle aurait pris 15 minutes à câbler. La leçon a coûté un client.
Au-delà des 3 règles minimales, deux règles de second niveau valent le coup à terme : (1) escalation par tier client (clients enterprise jamais en full IA, ils ont accès humain direct), et (2) escalation par scope produit (questions sur les nouvelles features de moins de 30 jours, pas encore stables dans le RAG, vont en humain par défaut). Ces deux règles font passer ton CSAT enterprise de 4,1 à 4,5 et évitent les hallucinations sur du code récent.
Ce qu'il faut faire cette semaine
Le support IA en 2026 n'est plus une question de "si", c'est une question de "comment". Ne pas le faire, c'est laisser 60-80 heures par mois sur la table et payer 12× le prix par ticket. Le faire mal, c'est cramer ton NPS en 4 semaines. Le faire bien, c'est libérer 3400€/mois en valeur de temps pour relancer le build.
Cette semaine, fais 3 choses dans l'ordre. Choisis ton helpdesk (Crisp si tu veux simple, Plain si tu fais du B2B technique). Construis ton vector store (embedding tes docs + tes 1000 derniers tickets résolus). Câble les 3 règles d'escalation (sentiment, keywords, timeout 30 min). Pas avant la semaine 2 tu lances en mode shadow. Pas avant la semaine 4 tu bascules en semi-auto. Le shortcut existe pas.
Dans le programme VibesMoney, on déploie ensemble ta stack support IA (helpdesk + RAG + 3 règles d'escalation), tu repars avec ton agent qui résout 70% de tes tickets dès le lundi suivant. 10 sessions live, 8 places par cohorte. Candidater au programme. Et pour boucler la chaîne d'acquisition, jette un œil à 100 leads B2B avec LinkedIn et IA : le support IA permet de soutenir le volume que ce playbook génère, sans recruter.

Alexis Dubain
Co-fondateur VibesMoney, fondateur Automascale. Je tourne le support de WhatSetter à 80% IA depuis février 2026, 600 tickets/mois pour 49€ de stack.
Tu veux ce setup support IA installé sur ton produit ?
Dans le programme VibesMoney, on déploie ensemble ta stack support IA (helpdesk + RAG + 3 règles d'escalation), tu repars avec ton agent qui résout 70% de tes tickets dès le lundi suivant. 10 sessions live, 8 places par cohorte.
JE LANCE MON SAAS →
